
Decision intelligence: moving from prediction to action
The purpose of collecting data is to learn from it; and we learn by asking questions. In the data world questions come in the form of estimators that construct some properties of the data. So what are the right questions to ask?
Say we have an estimator based on some (finite) data set, the most important criterion in judging whether this estimator any is ‘good’ is its behaviour as we increase the amount of data. Let us explain why. For anyone to take an estimator seriously we have to trust it. If adding one data points radically changes our opinion then we stop listening. After-all add another data point and we may change our opinion back. With this level of uncertainty we can’t be expected to make decisions. The convergence in the large data limit is a measure of stability. A lack of convergence indicates ill-posedness. In other words if we don’t converge then we are asking the wrong question. It probes something unknowable which no amount of data will tell us: the information is not in the data.
Studying the asymptotics is all about making sure we are asking the right question. We know why and now need to know how. First we should consider what we want. We want (1) our estimator to converge and (2) for it to converge to something meaningful. Many estimators can be written as solutions to a minimization problem, for example maximum likelihood, maximum a-posteriori, least square etc. We concentrate on estimators of this form.
Imagine that we have a sequence of minimization problems numbered according to the number of data points. The law of large numbers motivates a ‘limiting problem’ that we can understand as having an infinite number of data points. So then what is the natural notion of convergence for these sequence of minimization problems? Well, let’s recall what is motivating us: the convergence of minimizers!
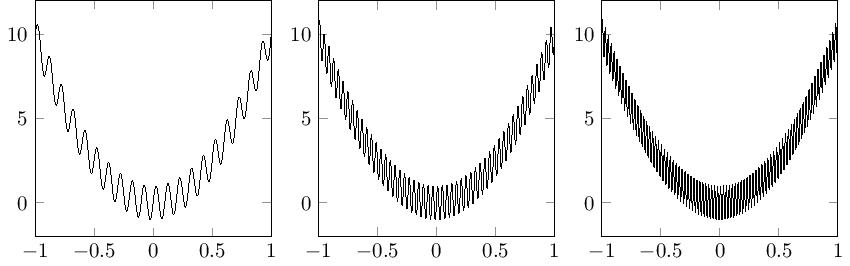
Roughness of such function will increase with the data and Γ-convergence is precisely the framework we need to deal with this. For those that have never come across Γ-convergence before, it was introduced by De Giorgi in the 1970’s and is most commonly used in the calculus of variations; particular in homogenisation, image processing and material science. It is also the natural convergence we need to imply not just that there is a convergent minimum but that the minimizers converge to to the right thing. Approximately speaking the Γ-limit is the ‘limiting lower semi-continuous envelope’. For the sequence of functions defined in the figure below we can see that whilst there is no limit in the strong sense the minimum and minimizers are well behaved. Weak convergence captures some behaviour, we can see that the minimizers converge to the minimizer of the weak limit, but the minimum does not (the minimum of the weak limit is 0, whilst the minimum for each of the sequence is approximately -1). The Γ-limit completely captures the behaviour of both the minimum and minimizers.

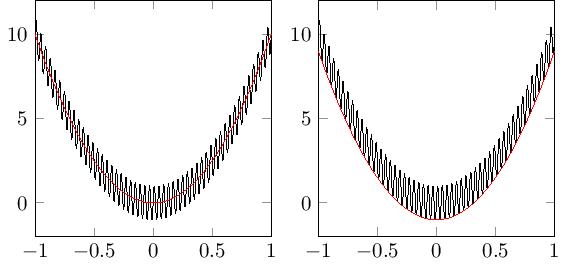
There are two criteria we must show to infer the convergence of minimizers. The first is to find the Γ-limit. Mostly this will be the law of large numbers limit. The second is to show that minimizers are uniformly bounded. This can take a bit of work but is worth it. If minimizers are not bounded then we have sequences of estimators diverging. This is the behaviour that we have to avoid if we want our question to be worth asking. Under these two conditions the Γ-convergence framework implies that the minimums converge and that (up to subsequences) minimizers are also convergent. Furthermore the limit of any subsequence of minimizers will minimize the Γ-limit. Hence if the Γ-limit has a unique minimizer then the entire sequence will converge (no longer subsequences!). Let us also emphasise that the limiting minimizer has meaning.
Hopefully we have convinced you that studying asymptotics is important and that Γ-convergence is more than just mathematical abstrusity. If your question is unanswerable with unlimited data you should not expect a useful answer for finite data. Are you sure that you are asking the right questions?
This Guest Blog was contributed by:
Matthew Thorpe, University of Warwick, Coventry, CV4 7AL, United Kingdom
Neil Cade, Selex-ES Ltd, Luton, LU1 3PG, United Kingdom
Office Address:
Willow Court, West Way, Minns
Business Park. Oxford OX2 0JB
+44 (0) 1865 244011
hello@smithinst.co.uk





Quality Policy | IT Security | Health and Safety Policy | Environment Policy | Business Continuity | Privacy Policy | This website uses cookies | Terms of Use
© Smith Institute 2026. All rights reserved. Website by Studio Global
Smith Institute Ltd is a company limited by guarantee registered in England & Wales number 03341743 with registered address at 1 Minster Court, Tuscam Way, Camberley, GU15 3YY


